Petit réseau neuronal
J’ai rassemblé ci-dessous des notes que j’ai prises en suivant les tutoriels vidéo de Daniel Shiffman sur les réseaux neuronaux, qui eux-mêmes s’inspirent largement de Make Your Own Neural Network, un livre écrit par Tariq Rashid. Les concepts et les formules ne sont pas de moi, je ne fais que les écrire afin de m’aider à les comprendre et à les mémoriser.
Algorithme de propagation avant
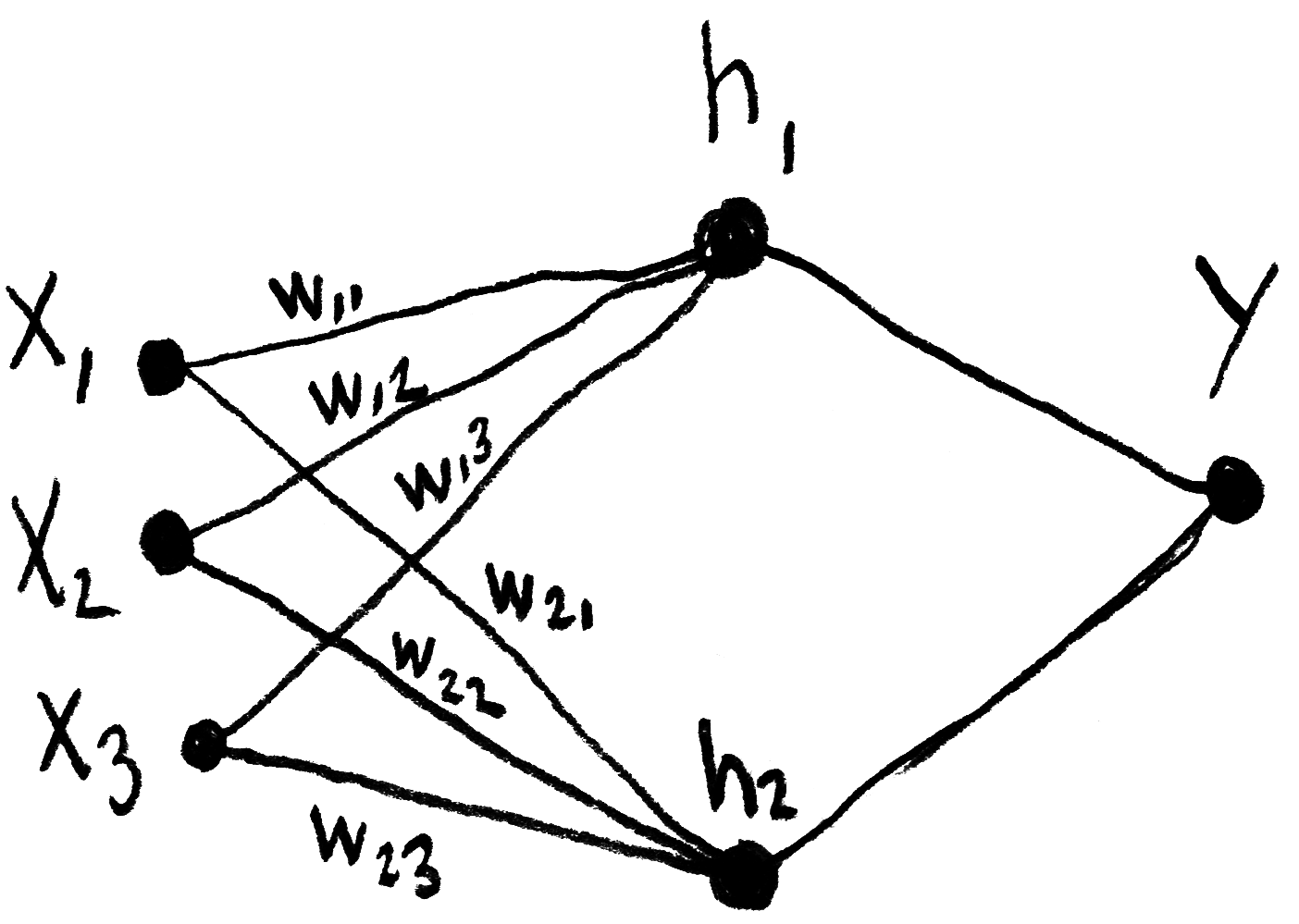
Le calcul réalisé par une des couches du réseau, qui se fait en considérant ses « poids synaptiques » (en anglais, “weights”), peut se résumer par le produit matriciel ci-dessous, dans lequel h représente une des couches intermédiaires (ou « couches cachées ») du réseau, w représente les poids et x représente les nœuds d’entrées (“inputs”) . Dans cette notation inversée, ⃗wij indique le poids de j vers i.
Ce produit peut aussi se représenter ainsi :
Il est aussi possible de le simplifier davantage :
Il faut aussi ajouter un biais B, dont la valeur est de 1.
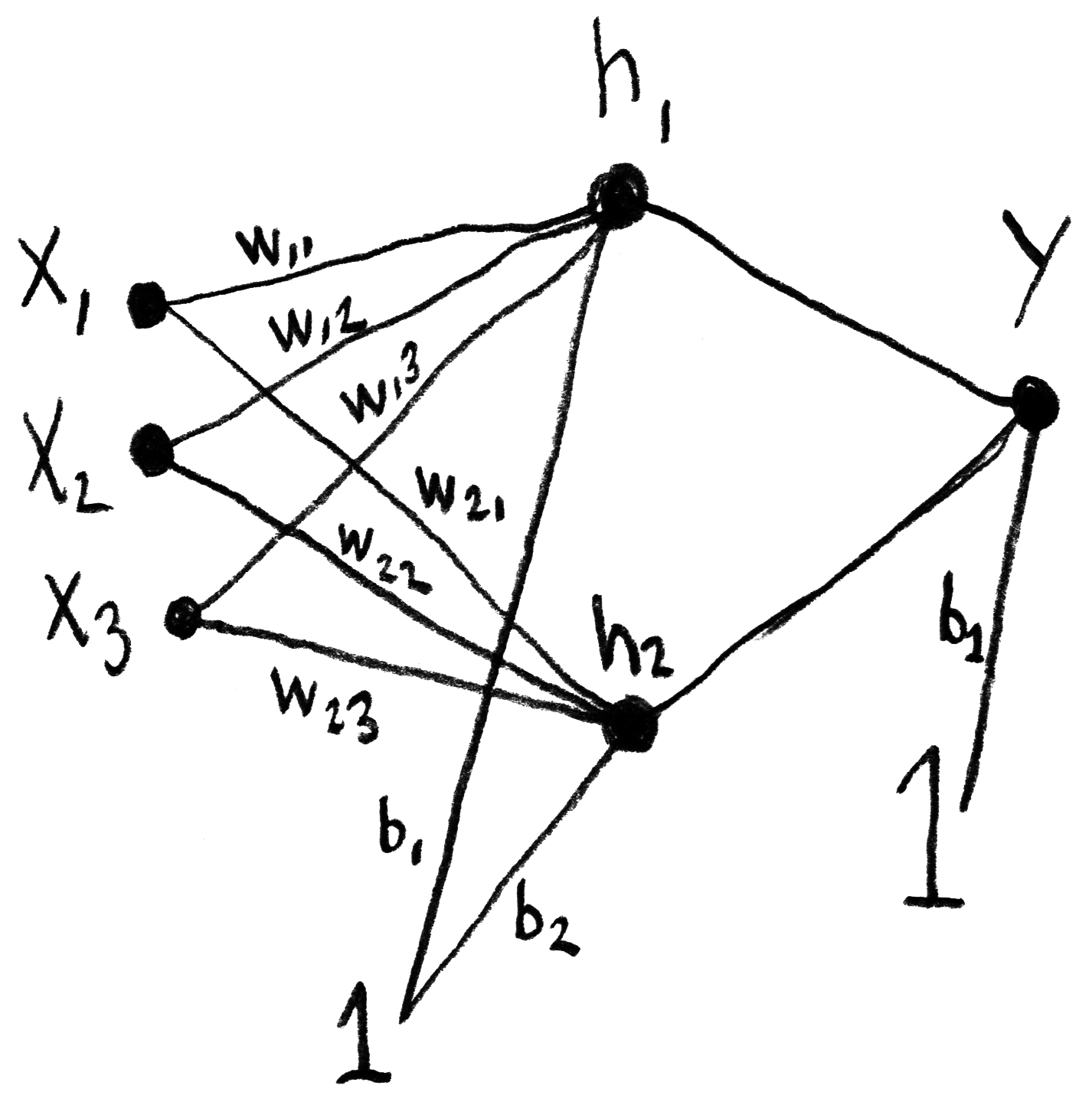
La fonction sigmoïde servira de fonction d’activation :
Le calcul du nœud de sortie Y se fera finalement de cette façon :
Rétropropagation du gradient
Une fois la propagation avant terminée, nous sommes en mesure de calculer l’erreur e, qui doit ensuite être envoyée du nœud de sortie vers les couches précédentes, par rétropropagation. Ici, ⃗wij représente le poids w entre le nœud de sortie j et la couche cachée i.
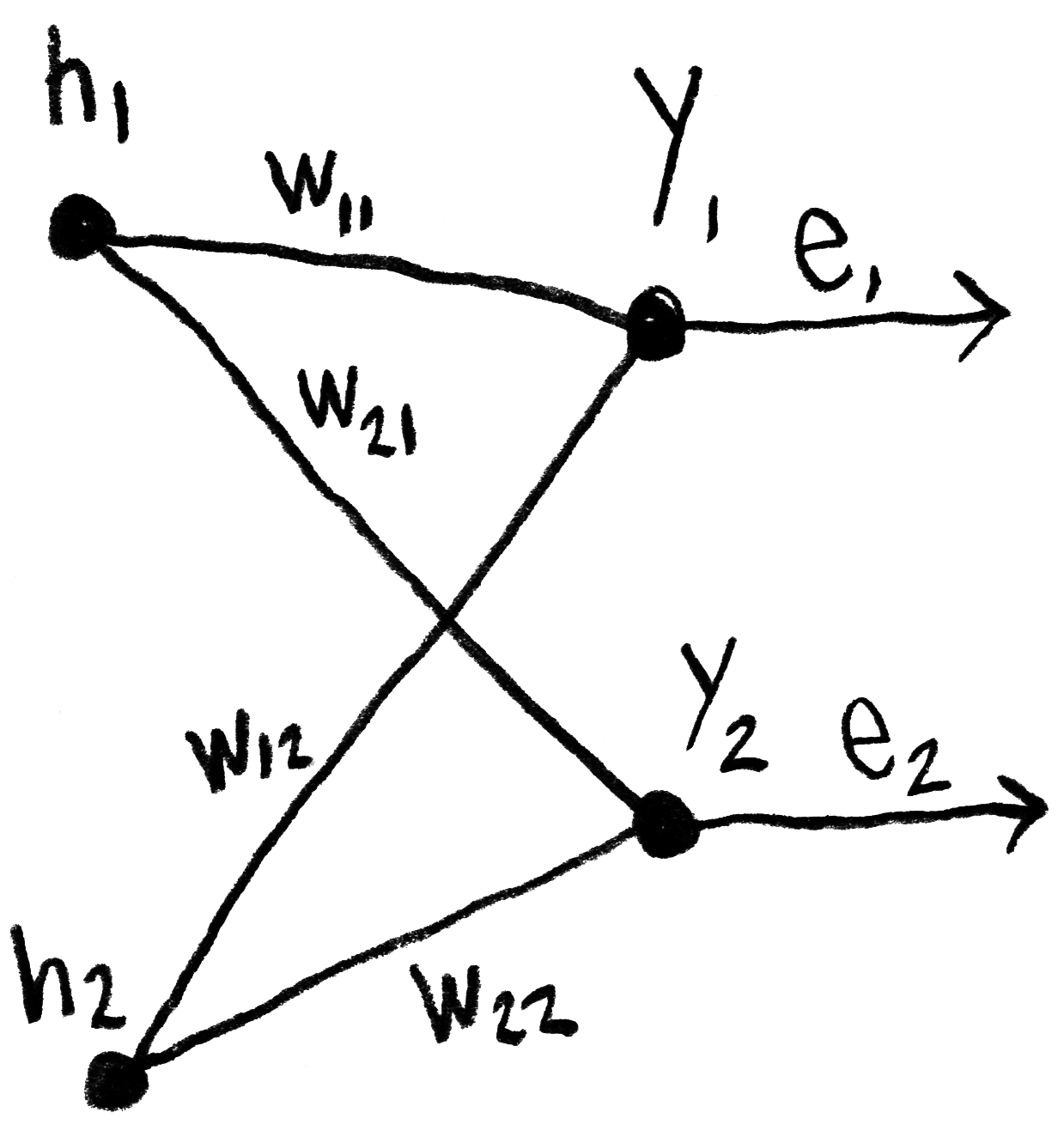
Nous allons cependant simplifier ce calcul en ne normalisant pas les poids avant de les multiplier avec l’erreur :
Ce qui équivaut à ce produit matriciel :
À noter que la matrice des poids qui était utilisée lors de la propagation avant a été transposée pour être utilisée lors de la rétropropagation.
Autres ressources
- — Machine Learning for the Web, un cours de Yining Shi donné à Itp (Nyu).
- — How to build a Teachable Machine with TensorFlow.js, un tutoriel de Nikhil Thorat (un des développeurs de TensorFlow.js).
- — Make your own neural network, de Tariq Rashid.
- — Essence de l’algèbre linéaire, une série de vidéos de la chaîne YouTube 3Blue1Brown.
- — Les réseaux neuronaux, une autre série de 3Blue1Brown.
- — Essence du calcul différentiel et intégral, une autre série de 3Blue1Brown. “Chain rule, product rule”.
- — Neural Networks and Deep Learning.
- — Essential Math for Machine Learning, un cours de Graeme Malcolm sur edX.
Contexte
Cette note de blog fait partie de mon projet de recherche Vers un cinéma algorithmique, démarré en avril 2018. Je vous invite à consulter la toute première note du projet pour en apprendre davantage.